Build Competitive Intelligence AI Agents: 10 Best Tools, APIs and MCPs [2026]
We tested the 10 best tools, APIs and MCPs for building competitive intelligence AI agents in 2026. See how KeepTabz, Trigify, Apify and 7 others stack up.
We tested the ten best tools for feeding competitive intelligence data into AI agents in 2026. The market splits into four layers: pre-structured CI data (KeepTabz), social and LinkedIn signal intelligence (Trigify, Bright Data), general-purpose web scraping (Apify, Firecrawl), and LLM-native search APIs (Exa, Tavily, SerpAPI). The right stack is usually two or three of these working together, not one tool doing everything. KeepTabz leads on signal coverage and MCP-native access; the others fill specific gaps depending on what you're building.
AI Agents Can't Build a Competitive Picture from Training Data Alone
Most teams building competitive intelligence agents in 2026 start the same way. They open Claude or ChatGPT, ask "what are my competitors doing this quarter," and watch the model invent quotes, hallucinate funding rounds, or summarize a year-old article as breaking news. The model isn't lazy. The competitive signal that matters (LinkedIn posts, ad creative, G2 reviews, pricing pages, hiring pages, changelogs) sits behind sources LLMs cannot crawl directly, and what they can crawl is often stale.
The fix is a data layer between the agent and the web. Some of these tools push pre-structured competitive intelligence over MCP. Some scrape any URL on demand and return LLM-ready Markdown. Some search the web semantically. Used together, they replace the wall of broken Chrome tabs that used to constitute "competitive research" with a CI agent that runs on real, current data.
We evaluated the ten best tools for building competitive intelligence AI agents in 2026, including KeepTabz, Trigify, Apify, Bright Data, Firecrawl, and five others. The comparison below covers pricing, signal coverage, MCP and API support, and where each tool sits in a working CI agent stack.
Shortlist
#
Tool
Best For
1
KeepTabz
Pre-structured competitive intelligence data delivered via MCP
2
Trigify
LinkedIn and social signal intelligence for AI agents
3
Apify
General-purpose web scraping with 25,000+ pre-built actors
Why Trust This Guide
KeepTabz powers a Competitive Intelligence MCP server that runs inside Claude, ChatGPT, Claude Code, Zapier, Make, and n8n stacks for hundreds of CI agent builders. We've used most of the tools in this list either as customers, integration partners, or directly inside our own agent prototypes. We have also personally tested a lot of these products, and actually use some of them to build the data layer of our own product, so we write this from first-hand experience. What you're reading is the stack we'd build if we were starting tomorrow.
What Is a Competitive Intelligence AI Agent?
A competitive intelligence AI agent is an LLM-powered workflow that pulls real-time competitor signals from the web, reasons over the signals, and outputs something useful: a battle card refresh, an executive market report, an outbound sequence, a feature gap analysis. The agent itself is usually Claude, ChatGPT, or an open-source model wrapped in a framework like LangChain, Claude Code, n8n, Make, or Zapier. The agent handles the reasoning. The tools in this list handle the data work.
Working CI agents tend to follow a four-step loop: pull signals from the web, structure and score them, reason over them with an LLM, and ship the output (Slack message, doc, slide, email). Most failure modes happen in step one. If the data is stale, hallucinated, or missing the channels that actually matter, the LLM produces confident-sounding garbage and the agent is worse than no agent.
How These Tools Improve Competitive Intelligence AI Agents
They reach the data LLMs cannot. Large language models cannot crawl LinkedIn, X, G2, Capterra, news wires, or ad libraries directly. The tools in this list have custom scrapers, licensed API partnerships, or persistent infrastructure to extract that signal cleanly.
They give the agent structure instead of raw HTML. A 30,000-token HTML blob is hard for an agent to reason over. Tools like Firecrawl, Exa, and KeepTabz return clean Markdown, scored events, or structured JSON so the LLM does less parsing and more thinking.
They cut token spend. Pre-structuring data on the way in means the LLM burns fewer tokens on extraction and more on actual analysis. KeepTabz, Tavily, and Exa all market this benefit directly.
They make the agent more accurate. Grounded retrieval reduces hallucination. A CI agent answering "did Notion change their pricing this month" off a Firecrawl snapshot will get it right. An agent answering off the model's training data will get it confidently wrong.
That said, these tools are not equally easy to adopt. Several of them (Apify, Bright Data, SerpAPI, Crunchbase API, BuiltWith) are built for engineering teams and need code to extract value. Most of them return a firehose of unstructured data the agent and LLM still have to filter, score, and interpret on the way through. And in some cases, especially with community-built scrapers, the data itself is unreliable enough that the agent needs error handling to compensate. The sections below call those tradeoffs out per tool so you can weight them against your team's skills and the time you have to build.
The 10 Best CI AI Agent Tools at a Glance
#
Tool
Best For
Key Features
Pricing
1
KeepTabz
Pre-structured CI data via MCP
Nine CI signals, AI scoring, MCP server, daily digest
From $59.99/mo
2
Trigify
LinkedIn + social signal for agents
30+ sales triggers, TrigIQ AI, LinkedIn without account risk
LangChain-first, Research endpoint, pre-ranked results
Free / from $100/mo
8
SerpAPI
Structured Google SERP data
80+ search engines, full SERP elements, 99.95% SLA
From $75/mo
9
Crunchbase API
Company and funding data
Funding rounds, acquisitions, people, predictions
From $49/mo
10
BuiltWith
Technographic data on competitors
Tech stack on 250M+ sites, historical adoption
From $295/mo
#1: KeepTabz
Best for: Pre-structured competitive intelligence data delivered to AI agents via MCP.
KeepTabz Competitive MCP Server connecting to Claude and ChatGPT, 2026
KeepTabz is the only tool on this list that pushes pre-structured, AI-scored competitive intelligence across nine signal types directly to an agent over MCP. Other tools on this list focus on raw scraping, search, or single-signal datasets. KeepTabz handles the steps an agent builder would otherwise have to assemble themselves: licensed access to LinkedIn, X, G2, Capterra, TrustRadius, news wires, and ad libraries; common-name competitor filtering; AI scoring of competitive importance with transparent rationale; and a single API surface that exposes every signal in one place.
Disclosure: KeepTabz is our platform. We've aimed to give a fair, evidence-based evaluation of how each of these tools fits into a working CI agent stack.
Key Features
Competitive MCP Server. A single API connection to Claude, ChatGPT, Claude Code, Zapier, Make, and n8n. Exposes nine CI signals (news, reviews, social, website changes, ad creative, SEO, PPC, pricing, messaging) per tracked competitor.
Pre-structured and pre-scored events. Every event arrives with an AI-scored competitive importance rating and a rationale, so the agent burns fewer tokens on extraction and more on reasoning.
Access to LLM-blocked sources. LinkedIn, X, G2, Capterra, TrustRadius, TrustPilot, news wires, and ad libraries all block LLM crawlers. KeepTabz pairs custom scrapers with licensed API partnerships for every one of them.
Six canonical agent workflows. Executive market reports, review analysis, social media analysis, website messaging analysis, ad teardowns, and dynamic battlecard refreshes are all documented patterns we see customers run on top of the MCP server. Vulnerability mining, content calendars, and competitive takeout sequences are common community-built workflows.
48-hour setup with human QA. Common-name filtering and competitor rules are configured during onboarding so agents inherit clean data instead of fighting false positives.
Daily Competitive Digest. Even non-builders get a working AI-curated competitive feed in Slack, Teams, Discord, or email without writing any agent code, which makes KeepTabz the natural starting point for teams graduating from "we should build an agent" to actually having one.
Pricing
KeepTabz offers a free 14-day trial on every plan. Paid pricing:
Lite ($59.99/month): 5 competitors, 3 users, 100 web pages tracked, daily digest. MCP server not included on this tier.
Core ($99.99/month, most popular): 10 competitors, 10 users, 200 web pages, daily digest, and the MCP server included.
Pro (call for pricing): Unlimited competitors, unlimited users, unlimited web pages, priority support, and the MCP server included.
Pros
Only tool on this list that bundles all nine canonical CI signals into one MCP and API surface.
Pre-scored events save tokens versus passing raw HTML through an LLM.
Coverage of LLM-blocked sources (LinkedIn, X, G2, Capterra, news wires, ad libraries).
Two-day setup with human QA, not an eight-week implementation.
$99.99/month gets you full MCP access, well below the enterprise CI tools that compete on data depth.
Customers without engineering get a working CI agent (the Daily Digest) before they write a line of code.
Cons
More opinionated than a generic scraper. If you need a custom data source KeepTabz doesn't track yet, you'll still need Apify, BrightData or Firecrawl alongside it.
MCP server requires the Core or Pro plan, not available on Lite.
Customer proof
"The first tool I've seen that captures the real-time data B2B marketers care about, from pricing shifts to social mentions," says Michelle Herman, VP of Marketing at Netlify.
RentBamboo built an entire outbound takeout sequence on top of the KeepTabz MCP, mining competitor reviews for outreach material. Read the RentBamboo story.
Best paired with: Firecrawl for ad-hoc URLs KeepTabz doesn't natively track. Exa or Tavily for open-ended semantic search. Trigify for individual-contributor LinkedIn signal at competitor accounts.
#2: Trigify
Best for: LinkedIn and social signal intelligence piped into AI agents without burning a LinkedIn account.
Trigify is a social intelligence engine that tracks LinkedIn engagement, comments, and conversation signals without requiring users to attach their own LinkedIn account credentials. The platform feeds thirty-plus named sales triggers (job changes, new follows, executive posts, comment threads, hiring spikes) into AI agents that can act on them, and a network of eighteen data providers enriches the resulting contact and company records. For competitive intelligence, Trigify is at its best watching what your competitors' executives and customers are saying on LinkedIn. Most CI tools cover company-level LinkedIn activity. Trigify goes deeper into the individual contributor and exec signal layer where strategic moves often appear weeks before they show up in a press release.
Key Features
TrigIQ AI agent. Signal interpretation, email copy suggestions, and recommended next actions for each trigger fired.
30+ sales triggers. Job changes, hiring spikes, executive post engagement, comment thread monitoring, follower growth, and more.
Safe LinkedIn monitoring. No account credential sharing. Trigify uses its own infrastructure to avoid burning your LinkedIn account.
Native integrations. HubSpot, Clay, Smartlead, plus webhook support for custom agent workflows.
Wide enrichment network. 18 data providers backing contact and company enrichment, plus 140K job boards and 250K news articles.
Pricing
Trigify offers a 14-day free trial. Paid pricing is customized based on scale and features, and Trigify doesn't publish a rate card. Contact their team for a quote.
Pros
LinkedIn-native without putting your LinkedIn account at risk.
Trigger-based workflow fits naturally into agent automation.
Strong fit for outbound sales agents that need account-change signal as a sales trigger.
Cons
Custom pricing only, less budget-friendly transparency than Apify or Firecrawl.
LinkedIn and social-first. You'll need other tools for website, ad, review, or pricing data.
Newer product with a smaller community than Apify or Bright Data.
Best paired with: KeepTabz for the broader nine-signal CI picture. Clay or HubSpot for outbound activation. Firecrawl for ad-hoc page scraping outside LinkedIn.
#3: Apify
Best for: General-purpose web scraping with 25,000+ pre-built Actors a competitive agent can call on demand.
Apify Actor marketplace web scraping platform, 2026
Apify is the largest marketplace of pre-built web scrapers, called Actors. Other tools focus on one or two data sources. Apify has more than 25,000 Actors covering everything from Google Maps to LinkedIn to Amazon to Shopify to Instagram. For an agent builder, Apify is the catch-all data layer. If you need to scrape a niche site that doesn't have its own API or pre-structured product, there's probably an Actor for it. If there isn't, you can write one in Apify's SDK and publish it for the rest of the community.
The catch is that Actor quality varies. The most popular Actors (Google Maps, LinkedIn jobs, Amazon product scrapers) are reliable and well-maintained. Niche Actors written by community members can break when target sites change their HTML, return empty results, or fail silently mid-run. For a CI agent that needs consistent data, expect to spend real time vetting Actors, watching for silent failures, and in some cases forking the Actor and maintaining your own version. This is engineering work. Non-developers can run a single Actor on demand, but standing up a multi-Actor agent pipeline assumes someone on the team owns the code.
Key Features
25,000+ pre-built Actors. LinkedIn, Instagram, TikTok, X, Amazon, Shopify, Google Maps, and dozens of niche targets.
Cloud platform for custom scrapers. Build, deploy, and run your own Actors in Apify's infrastructure.
Multiple execution paths. REST API, Python SDK, JavaScript SDK, web UI, and scheduled runs.
Native integrations. Slack, Google Sheets, Zapier, plus webhook support for any agent stack.
Proxy access included. Residential and datacenter proxies built into the platform.
Pricing
Apify has a free tier with $5 of platform credits per month. Paid plans are Starter at $29/month, Scale at $199/month, and Business at $999/month. Apify bills on Compute Units (1 GB RAM running for 1 hour); CU rates run from $0.13 at the Business tier to $0.20 on Free and Starter.
Pros
Largest marketplace of pre-built scrapers in the category.
Pay-as-you-go credit model fits agent workloads that vary by day.
Open community of Actor authors, with many high-quality and free options.
Strong free tier for prototyping a new agent before paying anything.
Cons
Compute-Unit billing can be hard to predict for agents that run wild.
Community Actor reliability is uneven. Popular Actors are well-maintained; niche ones break when target sites change their HTML, return empty results, or fail silently. CI agents need explicit error handling around any non-flagship Actor.
Built for engineering teams. Non-developers can run a single Actor on demand, but a working multi-Actor agent pipeline needs someone who owns the code.
Output is raw scraped records, not pre-scored CI events. The agent and LLM still have to filter, classify, and interpret the firehose on the way through.
Best paired with: KeepTabz for the structured CI signals. Firecrawl for clean Markdown extraction once you've grabbed a URL. Bright Data for premium proxies on tough targets.
#4: Bright Data
Best for: Premium residential proxies plus pre-structured datasets for high-volume agent workloads.
Note: We integrate data from Bright Data into our own product — it's genuinely a great tool and data source that we can't recommend highly eough.
Bright Data is the premium infrastructure layer for any agent that needs to scrape at scale. The company maintains one of the largest residential proxy networks in the world, plus a catalog of pre-built scrapers (called Web Scraper APIs) for LinkedIn, X, Amazon, eBay, and dozens of other targets. If KeepTabz is the pre-structured CI signal layer and Apify is the community-built scraper marketplace, Bright Data is the licensed-and-compliant infrastructure that runs underneath both.
Key Features
Web Scraper APIs. Pre-built scrapers for LinkedIn, X, Amazon, eBay, and others, priced from $0.75 per 1K records on promotion.
Web Unlocker, SERP API, Crawl API. $1 per 1K requests for the three workhorse endpoints.
Pre-built datasets. LinkedIn profiles, jobs, posts, companies. Subscription pricing from $250 per 100K records, scaling up to $50K+/month.
Enterprise compliance posture. GDPR and CCPA tooling, legal frameworks for sensitive sources, used by large organizations with formal procurement.
Pricing
API products start at $1 per 1K requests. Residential proxies at $2.50/GB on promo or $5/GB regular. Pre-built datasets range from $0.001 to $0.10 per record, or $500 to $50,000+/month on subscriptions. New accounts receive $25 to $50 in credits to test the platform before committing.
Pros
Strongest residential proxy network for hard scraping targets.
Pre-structured LinkedIn datasets remove the need to scrape LinkedIn yourself.
Compliance posture is enterprise-grade.
Cons
Pricing complexity. Multiple products, multiple billing models, and promo vs. regular rates that change. Non-developers struggle to forecast cost without an engineer's help.
Premium pricing versus Apify on overlapping use cases.
Heavier lift to integrate. Built for engineers, not no-code operators. Even the no-code dashboard assumes you can read a JSON spec.
Output is raw scraper records, not pre-structured CI events. The agent or LLM still has to filter, score, and interpret thousands of records to find what actually matters for your CI use case, so you will need to build this on top of the raw data.
Best paired with: KeepTabz for the AI-scored CI layer. Apify for community Actors that don't need premium proxies. Firecrawl when you need LLM-ready output and not just raw HTML.
#5: Firecrawl
Best for: Turning any URL into clean, LLM-ready Markdown an AI agent can reason over.
Note: We use Firecrawl's scrapers in parts of our own product. We can also call out that it's a great product and very dev-friendly.
Firecrawl LLM-ready Markdown web scraping for AI agents, 2026
Firecrawl is the scraping API agent builders reach for when they need to grab a page on demand and have the result come back as something an LLM can use without parsing. It handles JavaScript rendering, returns clean Markdown by default, and ships an official MCP server that plugs straight into Claude Desktop, Cursor, and Windsurf. For competitive intelligence agents that need to crawl a specific competitor URL ("scrape this changelog and tell me what shipped"), Firecrawl is the default tool in the AI developer community.
Key Features
LLM-ready Markdown output. Clean Markdown returned by default. No manual HTML cleaning required.
JavaScript rendering on every request. Handles SPAs and dynamically loaded sites without configuration.
Official MCP server. Plugs into Claude Desktop, Cursor, Windsurf, and VS Code for zero-glue integration.
Search, Extract, Map, and Crawl endpoints. Four primitives that cover most agent scraping use cases.
Multi-language SDKs. Python, Node.js, Go, and Rust SDKs plus webhook signing with HMAC-SHA256 for production workflows.
Pricing
Firecrawl has a free tier with 500 credits per month. Paid plans are Hobby at $19/month (3K credits), Standard at $99/month (100K credits), and Growth at $399/month (500K credits). Basic scrapes cost 1 credit per request. AI extraction costs 5 credits per request.
Pros
Cleanest LLM-ready output in the category. Markdown out of the box.
Official MCP server means zero glue code for Claude integrations.
Strong developer experience and active community.
Reasonable free tier for agent prototyping.
Cons
Pay-per-credit can add up at production volume. For most workflows you'll quickly find yourself on their $99/month plan.
AI extraction at 5 credits per call is meaningfully more expensive than basic scrapes.
Single-purpose scraper. You'll still need other tools for company data, social signal, or pre-structured CI.
Markdown output is clean but still raw page content. The agent has to filter, summarize, and decide what's relevant. Firecrawl handles extraction. It does not handle meaning.
Developer-first. The MCP server makes Claude integration easy, but everything beyond that (chaining requests, error handling, scheduling) assumes engineering involvement.
Best paired with: KeepTabz for structured CI signals. Apify for niche pre-built scrapers. Exa or Tavily for semantic search.
#6: Exa
Best for: Neural and semantic search across the web, optimized for agent latency.
Exa neural search API for AI agents, 2026
Exa is a search API built specifically for AI agents. Google and SerpAPI return keyword matches. Exa uses neural embeddings to find pages that match meaning. A CI agent asking "find software companies messaging on AI-native compliance" returns relevant pages even when none of those exact words appear together. In February 2026, Exa shipped Exa Instant, a sub-200ms neural search mode designed to remove the latency bottleneck that breaks agentic workflows running multi-step parallel search.
Key Features
Neural search by meaning. Semantic match instead of keyword match. Useful for CI research that doesn't reduce to a clean keyword.
Exa Instant. Sub-200ms neural search mode designed for real-time agent workflows.
LLM-ready content highlights. Clean parsed HTML, Markdown, and token-efficient highlights returned per result.
Find-similar mode. Pass a reference URL and get back semantically similar pages, useful for discovering competitive lookalikes.
Pricing
Exa has a free tier with 1,000 searches per month. Paid plans start at $40/month. Search with contents costs $7 per 1K requests (10 results, text and highlights), plus $1 per 1K additional results beyond 10. Exa Instant runs at $5 per 1K requests.
Pros
Neural search opens up "find by meaning" workflows keyword APIs cannot serve.
Sub-200ms agentic mode is unusual in the category.
Returns LLM-ready content highlights, not raw HTML.
Cons
Neural results can be unpredictable on highly specific queries.
Per-search cost is higher than Tavily's free tier and similar to SerpAPI at the developer level.
Best paired with: KeepTabz for structured CI. Firecrawl for deep page extraction once Exa surfaces the right URL. Tavily as a fallback search layer for LangChain-native stacks.
#7: Tavily
Best for: Search API purpose-built for LLM agents in LangChain, Claude, and similar frameworks.
Tavily search API for LLM agents, 2026
Tavily is the search API agent builders default to when working in LangChain, LlamaIndex, or Claude-based stacks. The product is built around the assumption that an LLM is the consumer: every search returns pre-ranked results with relevance scores, extracted content snippets, and an optional AI-generated answer. Tavily was acquired by Nebius in February 2026, which has reshuffled the competitive landscape for AI search APIs but hasn't slowed the product.
Key Features
Four endpoints in one API. Search, Extract, Map, and Crawl.
Search depth settings. Basic (faster, cheaper) versus advanced (slower, more sources scraped).
LangChain and LlamaIndex first-class integrations. Native nodes in both frameworks.
Research endpoint. Multi-step agent reasoning with built-in deep retrieval. Can consume up to 250 credits per request.
Pricing
Tavily has a free tier with 1,000 searches per month. Pay-as-you-go at $0.008 per credit. Bootstrap plan $100/month for 15,000 credits. Monthly plans bring per-credit cost down to $0.005 to $0.0075.
Pros
Built specifically for LLM agent workflows.
First-class integrations with LangChain and LlamaIndex.
Reasonable free tier for prototyping.
Nebius acquisition signals long-term investment in the product.
Cons
Research endpoint at 250 credits per call can burn through quotas fast.
Overlaps significantly with Exa. Most teams pick one or stack them carefully.
Acquisition-related changes may shift pricing or roadmap.
Best paired with: KeepTabz for structured CI signals. Firecrawl for deep page extraction. Apify for niche scrapers Tavily's Crawl endpoint won't reach.
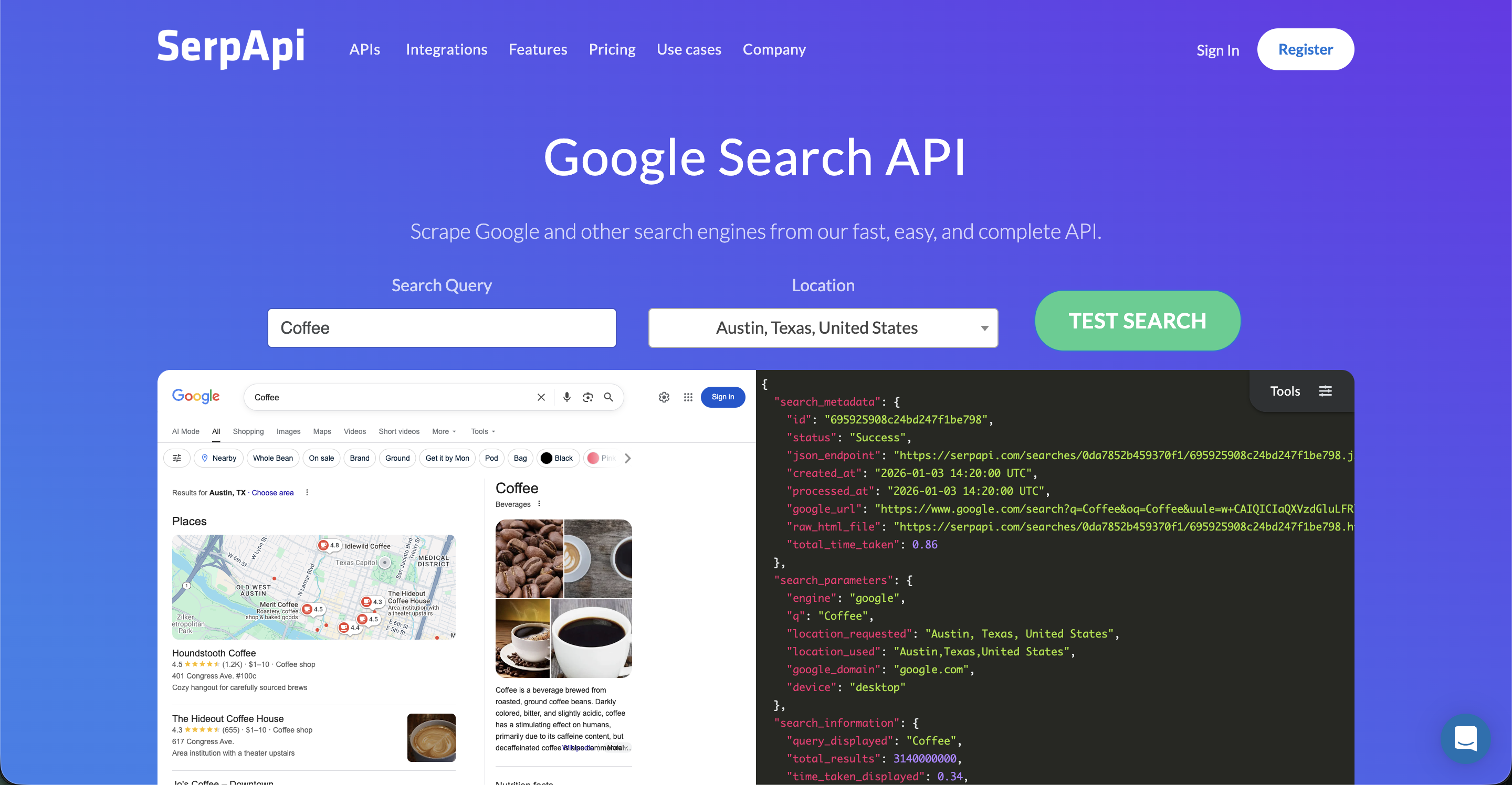
#8: SerpAPI
Best for: Structured Google search results plus 80+ other search engines for CI agents that need exact SERP data.
SerpAPI structured Google SERP results, 2026
SerpAPI is the workhorse Google SERP API the broader engineering community has used for years. Unlike neural search APIs like Exa or LLM-optimized APIs like Tavily, SerpAPI returns the actual Google search results page as structured JSON, including knowledge graphs, "People Also Ask" answers, sitelinks, dates, discussions, and videos. For a CI agent that needs to answer "what does Google show for [competitor brand]" or "what are competitors ranking on," SerpAPI gives you exact SERP data with high fidelity.
Key Features
80+ search engines covered. Google, Amazon, YouTube, Walmart, Bing, and more.
Full SERP elements. Knowledge graphs, PAA, sitelinks, dates, discussions, videos. Third-party benchmarks score it the richest SERP output in the category at 3.8/5.
Browser-rendered requests. Every request runs in a full browser with CAPTCHA solving included.
99.95% SLA. Service level agreement guaranteed on every paid plan, unusual for a data API.
Pricing
Developer plan at $75/month for 5,000 searches ($0.015 per search). Volume tiers bring the per-search cost down toward $0.005. A free tier exists with limited credits for prototyping.
Pros
Richest SERP output in the category by third-party benchmarks.
Coverage of 80-plus search engines beyond Google.
SLA guarantee is unusual for a data API and matters for production agents.
Browser-rendered means what you see is what users see.
Cons
Per-search cost is the highest in the AI search API category at scale.
Keyword-only. No neural or semantic search.
Built for engineering teams, not no-code operators. A non-developer cannot use SerpAPI without an engineer in the loop.
Output is a dense SERP JSON object with dozens of fields per request. Powerful for engineering teams. Overwhelming firehose for anyone trying to skim the results by hand.
Best paired with: KeepTabz for structured CI events. Exa or Tavily for semantic discovery layered on top. Firecrawl to deep-crawl the URLs SerpAPI surfaces.
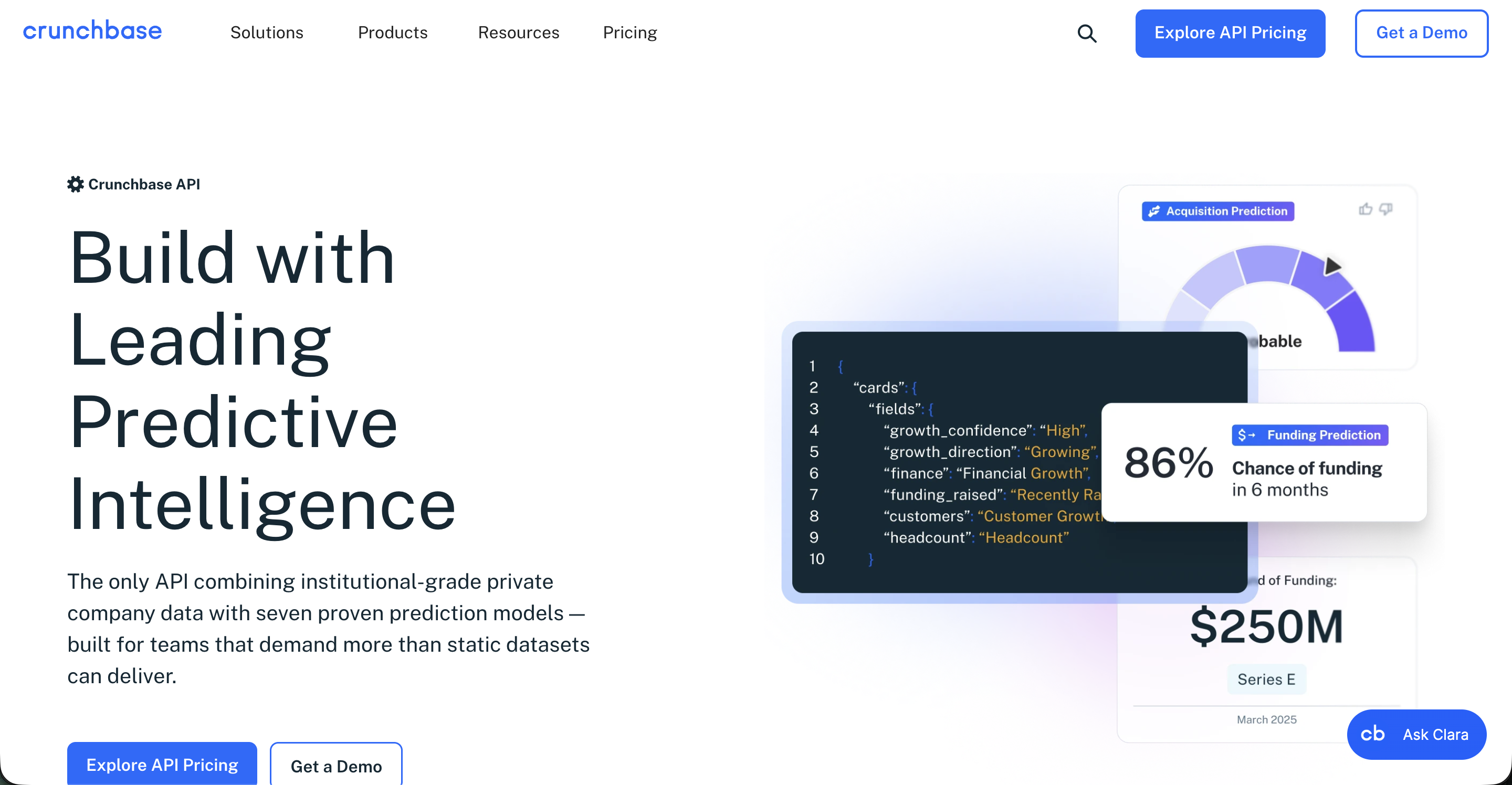
#9: Crunchbase API
Best for: Programmatic access to company, funding, and people data for CI agents tracking competitor financial signal.
Crunchbase API company and funding data, 2026
Crunchbase eliminated its free API tier in 2025, and the API is now part of a paid Basic ($49/month) or Pro ($99/month) subscription. For competitive intelligence agents that need to track funding rounds, acquisitions, leadership changes, and headcount estimates programmatically, Crunchbase is still the canonical source. The data isn't real-time the way news scraping is, but the structure and the historical completeness make it the right answer for agents building company-level firmographic context.
Key Features
200 API calls per minute on Pro. Adequate rate limit for most agent workloads.
Company, funding round, person, and acquisition data. Core entities with consistent schemas.
Predictions and scoring (Enterprise). Crunchbase's own predicted growth and ranking data exposed via API on the top tier.
Bulk exports and warehouse feeds. Available on Enterprise for teams loading Crunchbase into Snowflake or BigQuery.
Pricing
Basic at $49/month with limited API access. Pro at $99/month with full API. Enterprise pricing is custom and adds bulk exports, dedicated support, and predictions data.
Pros
Canonical source for funding and company data.
Well-documented API with a predictable schema.
Pro plan at $99/month is affordable for a working CI agent.
Cons
Free API tier eliminated in 2025.
Coverage is strongest for VC-backed and Series A+ companies. Weaker for bootstrap and small-business.
Data freshness lags news scraping by days to weeks.
The API itself is engineering-only. Non-developers should use the Crunchbase web app and let an engineer wire the API into the CI agent.
Best paired with: KeepTabz for real-time event signal that complements the firmographic baseline. Apify or Bright Data for LinkedIn enrichment on top of Crunchbase company records.
#10: BuiltWith
Best for: Technographic data on what tech stacks competitors and prospects are running.
BuiltWith technographic data competitor tech stack, 2026
BuiltWith is the canonical source for "what tech stack does this company use." The platform indexes more than 250 million websites and tracks current and historical technology adoption across analytics, CRM, payment processors, ecommerce, hosting, marketing automation, ad stack, and more. For a CI agent that needs to answer "which of competitor X's customers are still on Marketo" or "did this competitor just adopt our integration partner," BuiltWith is the right data source.
Key Features
Tech adoption across 250M+ sites. Largest technographic index in the category.
Current and historical tech stack. Trace when a domain added or removed a tool.
JSON API with AI-generated business insights. Categories, importance scores, and AI commentary returned per domain.
Add-on datasets. Ecommerce intel, lead generation, and analytics intel available as separate purchases.
Pricing
Basic at $295/month for 2 technologies tracked and 2,000 domain analyses per month. Pro at $495/month with unlimited tech tracking and 20,000 upload credits. Team at $995/month with 1.2 million API credits per year. The API uses a credit system on top of the base plan.
Pros
Canonical source for technographic data.
Historical tech stack data is unique in the category and useful for trend analysis.
Well-structured API with AI-generated business insights bundled in.
Cons
Highest entry-tier pricing in this list at $295/month.
Accuracy varies. Common technologies like Google Analytics and Shopify run 80-90% accurate; niche tools much lower.
Technographic-only. You'll need other tools for activity, social, and firmographic data.
Output is a long flat list of tech adoption signals per domain. Useful for an analyst or agent that can score it. Firehose for a non-developer trying to find the one signal that matters.
The web UI works for one-off lookups. The API requires engineering work to integrate into an agent.
Best paired with: KeepTabz for ongoing competitor activity. Crunchbase for funding context. Apify or Bright Data for LinkedIn enrichment to know which people at the competitor decided on the stack.
Build Your Stack: 4 Recommended Tool Combinations
Most working CI agents in 2026 use two or three of these tools together, not one. Below are four common stacks we see customers actually run. Pick the one closest to your use case and adjust from there.
Stack 1: The Lean CI Agent Starter Stack
For: Founders or solo PMM building a first competitive intelligence agent.
KeepTabz handles the nine canonical CI signals over MCP, so the agent gets a structured, pre-scored feed of competitor activity without any glue code. Firecrawl picks up ad-hoc URLs KeepTabz doesn't natively track (competitor changelogs, niche industry sites, partner pages). Tavily covers semantic search when the agent needs to research something open-ended. This is the stack we'd build for a first working agent.
Stack 2: The Outbound + Takeout Stack
For: Sales-led teams running competitive takeout campaigns at competitor accounts.
Approximate cost: $129/month, plus Trigify (custom).
KeepTabz feeds the agent competitor review and ad signal as the source material for outbound. Trigify surfaces LinkedIn job changes and engagement at competitor accounts so the agent knows which contacts to target. Apify Actors handle the long tail (G2 reviews, hiring pages, niche review sites). The agent assembles outbound sequences with specific, current pain points pulled from each competitor's own data. This is the stack RentBamboo built their outbound takeout play on.
Stack 3: The Enterprise CI Agent Stack
For: PMM or competitive intelligence teams at $50M+ companies running a formal CI program alongside an LLM.
Stack: KeepTabz Pro + Bright Data Web Scraper APIs + Exa + Crunchbase Pro.
Approximate cost: $2K to $5K/month depending on scrape and search volume.
KeepTabz Pro provides the structured nine-signal foundation across unlimited competitors and users. Bright Data scales the scraping for international competitor coverage and high-volume LinkedIn enrichment. Exa handles semantic discovery for analyst research workflows that don't reduce to a clean keyword. Crunchbase Pro keeps the firmographic context current. This stack handles the competitive workload of a Series C+ company without the eight-week implementation of an enterprise CI suite.
Stack 4: The Engineering Build-From-Scratch Stack
For: Engineering teams building a custom CI agent with full control over scoring, classification, and event detection.
Approximate cost: $200 to $500/month at moderate volume.
This stack skips the pre-structured CI layer in favor of full control. The team builds their own scoring, classification, and event detection on top of raw scraping and search APIs. More work, more flexibility. For teams without a strong reason to build from scratch, adding KeepTabz to this stack shortens the path to a working agent by months. For teams that have unique data requirements or want to own the entire pipeline, this is the right shape.
How to Choose the Right Tools for Your CI Agent
Step 1: Decide whether you're building or buying the structured CI layer
The single biggest decision is whether you want pre-structured competitive intelligence as a service (KeepTabz) or you want to build the scoring, classification, and event detection yourself on top of raw scraping and search APIs. The first path gets you to a working agent in days. The second path takes months but gives you full control. Most teams should buy. Teams with unique data requirements or unusual scoring needs should build.
Closely tied to that: who on your team will own the agent. Most of the tools in this list (Apify, Bright Data, SerpAPI, Crunchbase API, BuiltWith, and to a lesser extent Firecrawl, Exa, and Tavily) require engineering work to wire into an agent and keep running. They also return unstructured data that the agent or LLM has to filter, score, and interpret downstream. KeepTabz is the most non-developer-friendly option in the list because its MCP server connects to Claude in two clicks and the Daily Digest works without any code at all. If you don't have engineering bandwidth, weight the stack toward KeepTabz plus one MCP-native search or scraper tool, and hold the raw-API options until you have someone to own them.
Step 2: Map every signal source you actually need to reach
Write down every source the agent has to pull from: LinkedIn, X, G2, Capterra, news wires, ad libraries, competitor pricing pages, competitor changelogs, competitor hiring pages, Crunchbase, BuiltWith. Some of those are covered by a single tool (KeepTabz handles the first six; BuiltWith handles tech stack data). Some need a scraper (Firecrawl for changelogs, Apify for niche review sites). Mapping the sources first makes the tool selection obvious.
Step 3: Verify MCP or API support for your agent framework
If your agent runs in Claude, Cursor, or Windsurf, MCP support means zero glue code. KeepTabz, Firecrawl, and Apify (via community MCP servers) plug in directly. If your agent runs in LangChain or LlamaIndex, Tavily has first-class integrations. If you're working in n8n, Make, or Zapier, every tool in this list has a REST API or a native node. Check the integration shape before you sign up.
Step 4: Stress-test pricing at the volume your agent will actually run at
Free tiers and entry-level pricing make tools look cheap. Production volume is where the math changes. A CI agent making 500 searches a day against Tavily's $0.008 PAYG rate runs $120/month just on search. An Apify Actor that bills 0.5 CU per run, run 1,000 times per month, costs $80 on the Starter plan. Model the actual usage shape before committing.
Step 5: Test the full agent loop end-to-end before committing
A tool that looks great in isolation can break in the agent loop. The right test is the actual loop: pull the signal, hand it to the LLM, run the reasoning, ship the output. Most tools in this list offer a free tier or trial that's enough to test the loop on a single competitor for a week. Do that test before you sign annual contracts.
Wrapping Up: Stop Building CI Agents on Top of Stale Training Data
The bottleneck on a competitive intelligence agent isn't the model. Claude 4.6, GPT-5, and the open-source options can all reason fine over the right data. The bottleneck is whether the agent ever sees the right data in the first place. An LLM that can't reach LinkedIn, can't read G2, can't see the ad creative your competitor is running this week is going to invent its way to a confident wrong answer every time.
The fastest path to a working CI agent in 2026 is KeepTabz on Core ($99.99/month) for the structured nine-signal foundation, plus a scraping API (Firecrawl) and a search API (Tavily or Exa) on top for the long tail. For teams that need to go further, the stacks above scale up cleanly. For teams that need to start somewhere, that's the start.
Why can't I just use ChatGPT or Claude alone to track competitors?
Large language models cannot crawl LinkedIn, X, G2, Capterra, news wires, or ad libraries directly, so an LLM working from training data and open web fetches will miss most competitive signal and hallucinate the rest. A working competitive intelligence agent needs a data layer (KeepTabz, Trigify, Apify, Firecrawl, Bright Data) feeding it structured, current competitor activity over MCP or API.
What is the difference between an MCP server and a REST API for CI agents?
An MCP (Model Context Protocol) server is a standardized connection that lets AI assistants like Claude, ChatGPT, Cursor, and Windsurf call external tools and data sources directly. A REST API is a more general HTTP interface that any code can call. KeepTabz, Firecrawl, and several other tools in this guide ship official MCP servers so agents can pull competitive data with no glue code. Others expose a REST API that has to be wired into the agent through a framework like LangChain, n8n, or Zapier.
Can I build a competitive intelligence agent without writing code?
Yes. The KeepTabz MCP server connects to Claude Cowork, Claude Code, ChatGPT, and ChatGPT Pulse in two clicks, and the Daily Competitive Digest gives non-builders a working AI-curated CI feed without writing anything. For more custom workflows, no-code platforms like Zapier, Make, and n8n combine with the KeepTabz API and Firecrawl to build a CI agent without engineering involvement. And tools like Bright Data output as a JSON which the AI tools know how to read.
How much should I budget for a working CI agent stack?
A lean starter stack of KeepTabz Core ($99.99/month) plus Firecrawl Hobby ($19/month) plus a free tier of Tavily or Exa costs around $120/month and produces a working competitive intelligence agent. Mid-market stacks running at production volume tend to land between $400 and $1,500/month. Enterprise stacks with Bright Data, Crunchbase Pro, and high-volume Exa or Tavily usage typically run $2,000 to $5,000/month.
What's the difference between Exa, Tavily, and SerpAPI for AI agents?
SerpAPI returns structured Google search results pages (knowledge graphs, PAA, sitelinks) using keyword matching. Tavily and Exa are designed for LLM agents and return pre-ranked, content-extracted results that an agent can reason over directly. Tavily is the default in LangChain and LlamaIndex stacks. Exa uses neural search to match meaning, not exact keywords, and ships a sub-200ms agentic mode (Exa Instant).
![Build Competitive Intelligence AI Agents: 10 Best Tools, APIs and MCPs [2026]](https://cdn.prod.website-files.com/68100b769b154c0a404922e6/690fc0df354fc80ec6e11624_headshot1.png)
![Build Competitive Intelligence AI Agents: 10 Best Tools, APIs and MCPs [2026]](https://cdn.prod.website-files.com/68100b769b154c0a404922e6/6a1731b0827b550299242d74_KeepTabz-Building-CI-Agents-Guide-Header%20(1).png)
.png)